7. Programmation : interaction, structures de contrôle, |
7. Programmation : interaction, structures de contrôle, |
 Les "M-files" sont des fichiers au format texte (donc "lisibles") contenant des instructions MATLAB/Octave et portant l'extension *.m. On a vu la commande diary (au chapitre "Workspace") permettant d'enregistrer un "journal de session" qui, mis à part l'output des commandes, pourrait être considéré comme un M-file. Mais la manière la plus efficace de créer des M-files (c'est-à-dire "programmer" en langage MATLAB/Octave) consiste bien entendu à utiliser un éditeur de texte ou de programmation.
Les "M-files" sont des fichiers au format texte (donc "lisibles") contenant des instructions MATLAB/Octave et portant l'extension *.m. On a vu la commande diary (au chapitre "Workspace") permettant d'enregistrer un "journal de session" qui, mis à part l'output des commandes, pourrait être considéré comme un M-file. Mais la manière la plus efficace de créer des M-files (c'est-à-dire "programmer" en langage MATLAB/Octave) consiste bien entendu à utiliser un éditeur de texte ou de programmation.
On distingue fondamentalement deux types de M-files : les scripts (ou programmes) et les fonctions. Les scripts travaillent dans le workspace, et toutes les variables créées/modifiées lors de l'exécution d'un script sont donc visibles dans le workspace et accessibles ensuite interactivement ou par d'autres scripts. Les fonctions, quant à elles, n'interagissent avec le workspace ou avec le script-appelant principalement via leurs "paramètres" d'entrée/sortie, les autres variables manipulées restant internes (locales) aux fonctions.
MATLAB/Octave est un langage interprété (comme les langages Perl, Python, Ruby, PHP, les shell Unix...), c'est-à-dire que les M-files (scripts ou fonctions) n'ont pas besoin d'être préalablement compilés avant d'être utilisés (comme c'est le cas des langage classiques C/C++, Java, Fortran...). A l'exécution, des fonctionnalités interactives de debugging et de profiling permettent d'identifier les bugs et optimiser le code.
MATLAB et Octave étant de véritables "progiciels", le langage MATLAB/Octave est de "haut niveau" et offre toutes les facilités classiques permettant de développer rapidement des applications interactives évoluées. Nous décrivons dans les chapitres qui suivent les principales possibilités de ce langage dans les domaines suivants :
Les M-files étant des fichiers-texte, il est possible de les créer et les éditer avec n'importe quel éditeur de texte/programmation de votre choix. Idéalement, celui-ci devrait notamment offrir des fonctionnalités d'indentation automatique, de coloration syntaxique...
edit M-file ou edit('M-file') ou
open M-file ou open('M-file')
Sous MATLAB et sous Octave GUI, c'est l'éditeur intégré à ces IDE's qui est bien entendu utilisé. Si vous utilisez MATLAB ou Octave-CLI en ligne de commande dans une fenêtre terminal, voyez dans les chapitres qui suivent comment spécifier quel éditeur doit être utilisé.
 "Current folder" ou
"Current folder" ou  "File Browser")
New > Script | Function, File > New > New Script | New Function ou bouton New Script
"File Browser")
New > Script | Function, File > New > New Script | New Function ou bouton New Script
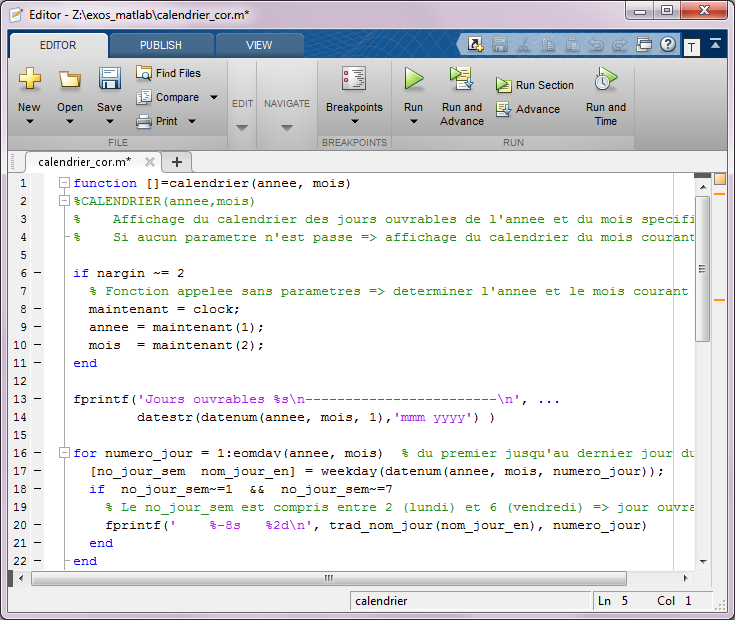
Quelques fonctionnalités pratiques de l'éditeur intégré de MATLAB :
setenv('EDITOR','path/editeur')
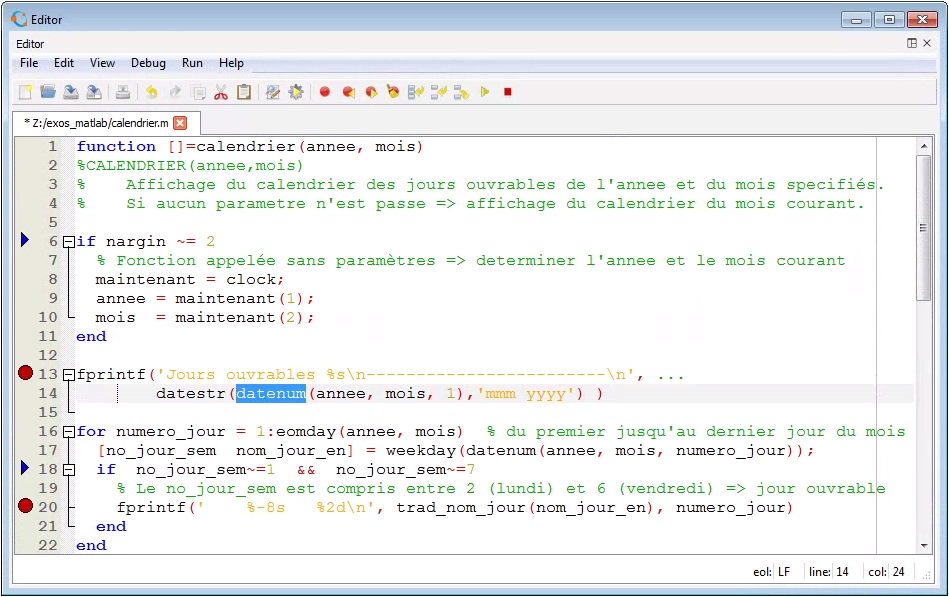
Quelques fonctionnalités pratiques de l'éditeur intégré de Octave GUI :
 Sous Windows cependant, c'est la console Command Window qui ne supporte pas les caractères spéciaux. Donc limitez-vous actuellement sous Windows aux caractères ASCII 7bit (non accentués...).
EDITOR('path/editeur') que l'on insère généralement dans son prologue .octaverc
Sous Windows cependant, c'est la console Command Window qui ne supporte pas les caractères spéciaux. Donc limitez-vous actuellement sous Windows aux caractères ASCII 7bit (non accentués...).
EDITOR('path/editeur') que l'on insère généralement dans son prologue .octaverc
Ex: Le morceau de script multi-plateforme ci-dessous teste sur quelle plateforme on se trouve et redéfinit ici "Gedit" comme éditeur par défaut dans le cas où l'on est sous Linux :
if ~isempty(findstr(computer,'linux'))
EDITOR('gedit') % définition de l'éditeur par défaut
edit('mode','async') % exécuter la commande "edit" de façon détachée
else
% on n'est pas sous Linux, ne rien faire de particulier
end
| Système | Éditeur conseillé | Définition de l'éditeur (pour prologue .octaverc) |
Indenter à droite, désindenter à gauche |
Commenter, décommenter |
| Multiplateforme | Atom | EDITOR('atom') | Edit>Lines>Indent (ou tab, ou alt-cmd-6) Edit>Lines>Outdent (ou maj-tab, ou alt-cmd-5) |
Edit>Toggle Comments (ou maj-cmd-7) |
| Windows | Notepad++ | EDITOR ('path/notepad++.exe') |
Edit>Indent>Increase (ou tab) Edit>Indent>Decrease (ou maj-tab) |
Edit>Comment/Uncom.> Toggle Block Comment (ou ctrl-Q) |
| Linux | Gedit (GNOME) | EDITOR('gedit') | tab maj-tab |
Edit>Comment Code (ou ctrl-M) Edit>Uncomment Code (ou ctrl-maj-M) (voir cependant ci-dessous) |
| macOS | TextWrangler | EDITOR('edit') | Text>Shift Right (ou cmd-]) Text>Shift Left (ou cmd-[) |
Il est nécessaire d'élaborer un "script TextWrangler"... |
Pour pouvoir mettre en commentaire un ensemble de lignes sélectionnées :
Affichage des caractères spéciaux tab, espace ... : en activant (et configurant) le plugin "Draw Spaces"
Pour automatiser certaines insertions (p.ex. structures de contrôles...) :
ifespace
tab
else
tab
end Pour être en mesure de développer des scripts MATLAB/Octave interactifs (affichage de messages, introduction de données au clavier...) et les "débugger", MATLAB et Octave offrent bon nombre de fonctionnalités utiles décrites dans ce chapitre.
disp(variable) disp('chaîne')
Ex: les commandes M=[1 2;3 5] ; disp('La matrice M vaut :') , disp(M) produisent l'affichage du texte "La matrice M vaut :" sur une ligne, puis celui des valeurs de la matrice M sur les lignes suivantes
{count=} printf('format', variable(s)...) Ex: si l'on a les variables v=444; t='chaîne de car.';, l'instruction fprintf('variable v= %6.1f et variable t= %s \n',v,t) affiche, sur une seule ligne : "variable v= 444.0 et variable t= chaîne de car."
 3:30 min |
Gestion d'erreurs et avertissements |
Les erreurs sont des évènements qui provoquent l'arrêt d'un script ou d'une fonction, avec l'affichage d'un message explicatif.
Les avertissements (warnings) consistent en l'affichage d'un message sans que le déroulement soit interrompu.
warning( {'id',} 'message') help warning_ids
error('message')
Sous Octave, si l'on veut éviter qu'à la suite du message d'erreur soit affiché un "traceback" de tous les appels de fonction ayant conduit à cette erreur, il suffit de terminer la chaîne message par le caractère "newline", c'est-à-dire définir error("message... \n"). Mais comme on le voit, la chaîne doit alors être définie entre guillemets et non pas entre apostrophes, ce qui pose problème à MATLAB. Une façon de contourner ce problème pour faire du code portable pour Octave et MATLAB est de définir error(sprintf('message... \n'))
Remarque générale : Lorsque l'on programme une fonction, si l'on doit prévoir des cas d'interruption pour cause d'erreur, il est important d'utiliser error(...) et non pas disp('message'); return, afin que les scripts utilisant cette fonction puissent tester les situations d'erreur (notamment avec la structure de contrôle try...catch...end).
a) variable=input('prompt') ; b) chaîne=input('prompt', 's') ;
a) En l'absence du paramètre 's', l'information entrée par l'utilisateur est "interprétée" (évaluée) par MATLAB/Octave, et c'est la valeur résultante qui est affectée à la variable spécifiée. L'utilisateur peut donc, dans ce cas, saisir une donnée de n'importe quel type et dimension (nombre, vecteur, matrice...) voire toute expression valide !
On peut, après cela, éventuellement détecter si l'utilisateur n'a rien introduit (au cas où il aurait uniquement frappé enter) avec : isempty(variable), ou length(variable)==0
b) Si l'on spécifie le second paramètre 's' (signifiant string), le texte entré par l'utilisateur est affecté tel quel (sans évaluation) à la variable chaîne indiquée. C'est donc cette forme-là que l'on utilise pour saisir interactivement du texte.
Dans les 2 cas, on place généralement, à la fin de cette commande, un ; pour que MATLAB/Octave "travaille silencieusement", c'est-à-dire ne quittance pas à l'écran la valeur qu'il a affectée à la variable.
pause off pour désactiver les éventuelles pauses qui seraient effectuées par un script (puis pause on pour rétablir le mécanisme des pauses).
|
19:17 min |
Les structures de contrôle sont un aspect fondamental de tous les langages de programmation. Il s'agit de constructions permettant d'exécuter des blocs d'instructions de façon itérative (boucle) ou sous condition (test). Nous présentons dans cette vidéo : • les boucles for, while et do/until, et l'effet dans celles-ci des instructions break et continue • le test if/elsif/else • la construction switch/case • le traitement d'erreurs avec try/catch, et les fonctions warning et error Mais avant de programmer des boucles (coûteuses en temps d'exécution), on réfléchira cependant toujours à deux fois, sous MATLAB/Octave (langages permettant le traitement natif de tableaux de N-dimension sans implémenter de boucles) s'il n'est pas possible de s'en passer, en programmant plutôt des expressions tirant parti des possibilités vectorisées de MATLAB/Octave (y.c. l'indexation logique qu'on présentera dans une prochaine vidéo), ce qui permet des gains de temps considérables lorsqu'on manipule de gros tableaux (millions d'éléments). |
Les "structures de contrôle" sont, dans un langage de programmation, des constructions permettant d'exécuter des blocs d'instructions de façon itérative (boucle) ou sous condition (test). MATLAB/Octave offre les structures de contrôle de base typiques présentées dans le tableau ci-dessous et qui peuvent bien évidemment être "emboîtées" les unes dans les autres. Notez que la syntaxe est différente des structures analogues dans d'autres langages (C, Java, Python).
Comme MATLAB/Octave permet de travailler en "format libre" (les caractères espace et tab ne sont pas significatifs), on recommande aux programmeurs MATLAB/Octave de bien "indenter" leur code, lorsqu'ils utilisent des structures de contrôle, afin de faciliter la lisibilité et la maintenance du programme.
Octave propose aussi des variations aux syntaxes présentées plus bas, notamment : endfor, endwhile, endif, endswitch, end_try_catch, ainsi que d'autres structures telles que:
unwind_protect body... unwind_protect_cleanup cleanup... end_unwind_protect
Nous vous recommandons de vous en passer pour que votre code reste portable !
| Structure | Description |
| Boucle for...end
for var = tableau instructions... end |
Considérons d'abord le cas général où tableau est une matrice 2D (de nombres, de caractères, ou cellulaire... peu importe). Dans ce cas, l'instruction for parcourt les différentes colonnes de la matrice (c'est-à-dire matrice(:,i)) qu'il affecte à la variable var qui sera ici un vecteur colonne. À chaque "itération" de la boucle, la colonne suivante de matrice est donc affectée à var, et le bloc d'instructions est exécuté.
Si tableau est un vecteur, ce n'est qu'un cas particulier : Si l'on a tableau à 3 dimensions, for examinera d'abord les colonnes de la 1ère "couche" du tableau, puis celles de la seconde "couche", etc... Ex:
|
| Boucle parfor...end
parfor (var=deb:fin {, max_threads})
instructions...
end
|
Variante simplifiée mais parallélisée de la boucle for...end : • le bloc d'instructions est exécuté parallèlement en différents threads (au maximum max_threads) sur plusieurs cores de CPU, l'ordre d'itération n'étant cependant pas garanti • deb et fin doivent être des entiers, et fin > deb |
| Boucle while...end ("tant que" la condition n'est pas fausse)
while expression_logique instructions... end |
Si l'expression_logique est satisfaite, l'ensemble d'instructions spécifiées est exécuté, puis l'on reboucle sur le test. Si elle ne l'est pas, on saute aux instructions situées après le end. On modifie en général dans la boucle des variables constituant l'expression_logique, sinon la boucle s'exécutera sans fin (et on ne peut dans ce cas en sortir qu'avec un ctrl-C dans la fenêtre console !) S'agissant de l'expression_logique, cela ne doit pas nécessairement être un scalaire ; ce peut aussi être un tableau de dimension quelconque, et dans ce cas la condition est considérée comme satisfaite si tous les éléments ont soit la valeur logique True soit des valeurs différentes de 0. A contrario elle n'est pas satisfaite si un ou plusieurs éléments ont la valeur logique False ou la valeur 0. Ex:
|
| Boucle do...until ("jusqu'à ce que" une condition se vérifie)
do instructions... until expression_logique |
Propre à Octave, cette structure de contrôle classique permet d'exécuter des instructions en boucle tant que l'expression_logique n'est pas satisfaite. Lorsque cette expression est vraie, on sort de la boucle. Voir plus haut au chapitre while...end ce qu'il faut entendre par expression_logique.
La différence par rapport à la boucle while est que l'on vérifie la condition après avoir exécuté au moins une fois le bloc d'instructions. Pour atteindre le même but sous MATLAB, on pourrait faire une boucle sans fin de type while true instructions... end à l'intérieur de laquelle on sortirait par un test et l'instruction break (voir plus bas). |
| Test if...elseif...else...end ("si, sinon si, sinon")
if expression_logique_1
instructions_1...
{ elseif expression_logique_i
instructions_i... }
{ else
autres_instructions... }
end
|
Si l'expression_logique est satisfaite, le bloc instructions_1 est exécuté, puis on saute directement au end sans faire les éventuels autres tests elseif. Sinon (si l'expression_logique_1 n'est pas satisfaite), MATLAB/Octave examine tour à tour les éventuelles clauses elseif. Si l'une d'entre elles est satisfaite, le bloc instructions_i correspondant est exécuté, puis on saute directement au end (sans tester les autres clauses elseif). Si aucune expression_logique n'a été satisfaite et qu'on a défini une clause else, le bloc autres_instructions correspondant est exécuté.
Noter que les blocs elseif ainsi que le bloc else sont donc facultatifs ! Ex:
|
| Construction switch...case...otherwise...end
switch expression
case val1
instructions_a...
case {val2, val3 ...}
instructions_b...
{ otherwise
autres_instructions... }
end
|
Cette structure de contrôle réalise ce qui suit : si l'expression spécifiée (qui peut se résumer à une variable) retourne la valeur val1, seul le bloc d'instructions_a qui suit est exécuté. Si elle retourne la valeur val2 ou val3, seul le bloc de instructions_b correspondant est exécuté... et ainsi de suite. Si elle ne retourne rien de tout ça et qu'on a défini une clause otherwise, c'est le bloc des autres_instructions correspondant qui est exécuté.
Important : notez bien que si, dans une clause case, vous définissez plusieurs valeurs val possibles, il faut que celles-ci soient définies sous la forme de tableau cellulaire, c'est-à-dire entre caractères { }.
Contrairement au "switch" du langage C, il n'est pas nécessaire de définir des break à la fin de chaque bloc. Ex:
|
| Construction try...catch...end
try instructions_1... catch instructions_2... end autres_instructions... |
Cette construction sert à implémenter des traitements d'erreur.
Les instructions comprises entre try et catch (bloc instructions_1) sont exécutées jusqu'à ce qu'une erreur se produise, auquel cas MATLAB/Octave passe automatiquement à l'exécution des instructions comprises entre catch et end (bloc instructions_2). Le message d'erreur ne s'affiche pas mais peut être récupéré avec la commande lasterr. Si le premier bloc de instructions_1 s'exécute absolument sans erreur, le second bloc de instructions_2 n'est pas exécuté, et le déroulement se poursuit avec autres_instructions |
| Sortie anticipée d'une boucle
break |
A l'intérieur d'une boucle for, while ou do, cette instruction permet, par exemple suite à un test, de sortir prématurément de la boucle et de poursuivre l'exécution des instructions situées après la boucle. Si 2 boucles sont imbriquées l'une dans l'autre, un break placé dans la boucle interne sort de celle-ci et continue l'exécution dans la boucle externe. A ne pas confondre avec return (voir plus bas) qui sort d'une fonction, respectivement interrompt un script ! Ex: sortie d'une boucle for : for k=1:100
k2=k^2;
fprintf('carré de %3d = %5d \n',k,k2)
if k2 > 200 break, end % sortir boucle lorsque k^2 > 200
end
fprintf('\nsorti de la boucle à k = %d\n',k)
Ex: sortie d'une boucle while : k=1;
while true % à priori boucle sans fin !
fprintf('carré de %3d = %5d \n', k, k^2)
if k >= 10 break, else k=k+1; end
% ici on sort lorsque k > 10
end
|
| Sauter le reste des instructions d'une boucle et continuer d'itérer
continue |
A l'intérieur d'une boucle (for ou while), cette instruction permet donc, par exemple suite à un test, de sauter le reste des instructions de la boucle et passer à l'itération suivante de la même boucle.
Ex: start=1; stop=100; fact=8;
fprintf('Nb entre %u et %u divisibles par %u : ',start,stop,fact)
for k=start:1:stop
if rem(k,fact) ~= 0
continue
end
fprintf('%u, ', k)
end
disp('fin')
Le code ci-dessus affiche: "Nb entre 1 et 100 divisibles par 8 :
8, 16, 24, 32, 40, 48, 56, 64, 72, 80, 88, 96, fin"
|
| double(var) | Cette instruction permet de convertir en double précision la variable var qui, dans certaines constructions for, while, if, peut n'être qu'en simple précision |
Les structures de contrôle sont donc des éléments de langage extrêmement utiles. Mais dans MATLAB/Octave, il faut "penser instructions matricielles" (on dit aussi parfois "vectoriser" son algorithme) avant d'utiliser à toutes les sauces ces structures de contrôle qui, du fait que MATLAB est un langage interprété, sont beaucoup moins rapides que les opérateurs et fonctions matriciels de base !
Ex: l'instruction y=sqrt(1:100000); est beaucoup plus efficace/rapide que la boucle for n=1:100000, y(n)=sqrt(n); end (bien que, dans les 2 cas, ce soit un vecteur de 100'000 éléments qui est créé contenant les valeurs de la racine de 1 jusqu'à la racine de 100'000). Testez vous-même !
|
19:16 min |
Les "scripts" sont la dénomination des programmes sous MATLAB/Octave. Dans cette vidéo nous voyons : • ce qui caractérise un script • comment un script peut interagir avec l'extérieur, que ce soit à travers le workspace, ou interactivement avec l'utilisateur • comment on peut documenter un script ainsi qu'élaborer une aide en-ligne facilitant son utilisation • comment utiliser efficacement l'éditeur intégré des environnements de développement Octave et MATLAB • ce qu'est le "prologue utilisateur" sous MATLAB/Octave |
Un "script" ou "programme" MATLAB/Octave n'est rien d'autre qu'une suite de commandes MATLAB/Octave valides (par exemple un "algorithme" exprimé en langage MATLAB/Octave) sauvegardées dans un M-file, c'est-à-dire un fichier avec l'extension .m.
Par opposition aux "fonctions" (voir chapitre suivant), les scripts sont invoqués par l'utilisateur sans passer d'arguments, car ils opèrent directement dans le workspace principal. Un script peut donc lire et modifier des variables préalablement définies (que ce soit interactivement ou via un autre script), ainsi que créer de nouvelles variables qui seront accessibles dans le workspace (et à d'autres scripts) une fois le script exécuté.
À partir de la version R2016B de MATLAB, il est possible de définir des fonctions à l'intérieur d'un script (ce qui n'était auparavant pas supporté sous MATLAB). Il faut cependant prendre garde au fait que :
Pour exécuter un script, on peut utiliser l'une des méthodes suivantes, selon que l'on soit dans l'éditeur intégré, dans la console MATALAB/Octave ou depuis un autre script :
Run, Save File and Run ou F5 source('{chemin/}script.m') ou source {chemin/}script.m
a) Lancement de l'exécution depuis l'éditeur intégré MATLAB ou Octave GUI
b) Le script doit obligatoirement se trouver dans le répertoire courant ou dans le path de recherche MATLAB/Octave (voir chapitre "Environnement"). Il ne faut pas spécifier l'extension .m du script
c) Cette forme permet d'exécuter un script situé en dehors du répertoire courant en indiquant le chemin d'accès (absolu ou relatif). On peut omettre ou spécifier l'extension .m du script
d) Cette forme est propre à Octave. Dans ce cas l'extension .m doit obligatoirement être indiquée
En phase de debugging, on peut activer l'affichage des commandes exécutées par le script en passant la commande echo on avant de lancer le script, puis désactiver ce "traçage" avec echo off une fois le script terminé.
Exemple de script: Le petit programme ci-dessous réalise la somme et le produit de 2 nombres, vecteurs ou matrices (de même dimension) demandés interactivement. Notez bien la 1ère ligne de commentaire (H1-line) et les 2 lignes qui suivent fournissant le texte pour l'aide en-ligne. On exécute ce programme en frappant somprod (puis répondre aux questions interactives...), ou l'on obtient de l'aide sur ce script en frappant help somprod.
%SOMPROD Script réalisant la somme et le produit de 2 nombres, vecteurs ou matrices
%
% Ce script est interactif, c'est-à-dire qu'il demande interactivement les 2 nombres,
% vecteurs ou matrices dont il faut faire la somme et le produit (élément par élément)
V1=input('Entrer 1er nombre (ou expression, vecteur ou matrice) : ') ;
V2=input('Entrer 2e nombre (ou expression, vecteur ou matrice) : ') ;
if ~ isequal(size(V1),size(V2))
error('les 2 arguments n''ont pas la meme dimension')
end
%{
1ère façon d'afficher les résultats (la plus propre au niveau affichage,
mais ne convenant que si V1 et V2 sont des scalaires) :
fprintf('Somme = %6.1f Produit = %6.1f \n', V1+V2, V1.*V2)
2ème façon d'afficher les résultats :
Somme = V1+V2
Produit = V1.*V2
%}
% 3ème façon (basique) d'afficher les résultats
disp('Somme =') , disp(V1+V2)
disp('Produit =') , disp(V1.*V2)
return % Sortie du script (instruction ici pas vraiment nécessaire,
% vu qu'on a atteint la fin du script !)
Pour autant qu'il ne soit pas interactif, on peut exécuter un script depuis un shell (dans fenêtre de commande du système d'exploitation) ou en mode batch (p.ex. environnement GRID), c'est-à-dire sans devoir démarrer l'interface-utilisateur MATLAB/Octave, de la façon décrite ici.
Avec MATLAB :
Avec Octave :
Notez que, dans ces commandes :
Ex: le script ci-dessous produit un fichier de données "job_results.log" et un graphique "job_graph.png" :
% Exemple de script MATLAB/Octave produisant des données et un graphique % que l'on peut lancer en batch avec : % matlab -nosplash -nodisplay -nodesktop -r job_matlab > job_results.log % octave --silent --no-window-system --norc job_matlab.m > job_results.log data = randn(100,3) fig = figure; plotmatrix(data, 'g+'); saveas(fig, 'job_graph.png', 'png') quit
En outre avec Octave, si vous ne désirez exécuter en "batch" que quelques commandes sans faire de script, vous pouvez procéder ainsi :
Ex: la commande octave -qf --eval "disp('Hello !'), arguments=argv(), a=12; douze_au_carre=12^2, disp('Bye...')" affiche :
Hello !
arguments =
{
[1,1] = -qf
[2,1] = --eval
[3,1] = disp('Hello'), arguments=argv(), a=12; douze_au_carre=12^2, disp('Bye...')
}
douze_au_carre = 144
Bye...
Étant donné les différences qui peuvent exister entre MATLAB et Octave (p.ex. fonctions implémentées différemment ou non disponibles...), si l'on souhaite réaliser des scripts portables (i.e. qui tournent à la fois sous MATLAB et Octave, ce qui est conseillé !) on peut implémenter du code conditionnel relatif à chacun de ces environnements en réalisant, par exemple, un test via une fonction built-in appropriée.
Ex: on test ici l'existence de la fonction built-in OCTAVE_VERSION (n'existant que sous Octave) :
if exist('OCTAVE_VERSION') % Octave
% ici instruction(s) pour Octave
else % MATLAB
% ici instruction(s) équivalente(s) pour MATLAB
end|
17:15 min |
Les fonctions utilisateur sont fondamentales en programmation, permettant notamment de rendre un code plus modulaire, plus lisible et moins redondant. Nous montrons dans cette vidéo : • ce qui distingue fondamentalement les fionctions des scripts (présentés dans une vidéo précédente), au niveau de leur implémentation et de leur utilisation, notamment la question du passage d'arguments en entrée et la récupération de données en sortie • la portée et la durée de vie des variables au sein des fonctions, et comment modifier cela (avec les instructions global et persistent) • ce qu'il est possible de faire, s'agissant de la combinaison, dans un même M-file, de plusieurs fonctions |
Également programmées sous la forme de M-files, les "fonctions" MATLAB/Octave se distinguent des "scripts" par la manière de les utiliser. On les appelle ainsi :
[variable(s) de sortie ...] = nom_fonction(paramètre(s) d'entree ...)
Le mécanisme de passage des paramètres à la fonction s'effectue "par valeur" (c'est-à-dire copie) et non pas "par référence". La fonction ne peut donc pas modifier les variables d'entrée au niveau du script appelant (workspace principal) ou de la fonction appelante (workspace de cette dernière).
Les variables créées à l'intérieur de la fonction sont dites "locales", c'est-à-dire qu'elles sont par défaut inaccessibles en dehors de la fonction (que ce soit dans le workspace principal ou dans d'autres fonctions ou scripts). Chaque fonction dispose donc de son propre workspace local de fonction.
Il est possible de définir, dans le même M-file, plusieurs fonctions à la suite les unes des autres. Cependant seule la première fonction du M-file, appelée fonction principale (main function), sera accessible de l'extérieur. Les autres, appelées fonctions locales (ou subfunctions), ne pourront être appelées que par la fonction principale ou les autres fonctions locales du M-file.
Il est finalement possible de définir des fonctions à l'intérieur du corps d'une fonction. Ces fonctions imbriquées (nested function) ne pourront cependant être invoquées que depuis la fonction dans laquelle elles sont définies.
Le code de toute fonction débute par une ligne de déclaration de fonction qui définit son nom_fonction et ses arguments args_entree et args_sortie (séparés par des virgules), selon la syntaxe :
function [argument(s)_de_sortie, ...] = nom_fonction(argument(s)_d_entree, ...)
Octave affiche un warning si le nom de la fonction principale (tel que défini dans la 1ère déclaration de fonction) est différent du nom du M-file. Sous MATLAB, le fait que les 2 noms soient identiques n'est pas obligatoire mais fait partie des règles de bonne pratique.
Se succèdent donc, dans le code d'une fonction (et dans cet ordre) :
endfunction, mais nous vous suggérons de la remplacer par end afin que vos fonctions soient compatibles à la fois pour MATLAB et Octave. Mais en fait sous MATLAB et Octave, l'instruction end finale d'une fonction peut aussi être omise, sauf lorsque l'on définit plusieurs fonctions dans un même M-file.
Exemple de fonction: On présente, ci-dessous, deux façons de réaliser une petite fonction retournant le produit et la somme de 2 nombres, vecteurs ou matrices. Dans les deux cas, le M-file doit être nommé fsomprod.m (c'est-à-dire identique au nom de la fonction). On peut accéder à l'aide de la fonction avec help fsomprod, et on affiche la première ligne d'aide en effectuant par exemple une recherche lookfor produit. Dans ces 2 exemples, mis à part les arrêts en cas d'erreurs (instructions error), la sortie s'effectue à la fin du code mais aurait pu intervenir ailleurs (instructions return) !
| Fonction | Appel de la fonction |
function resultat = fsomprod(a,b)
%FSOMPROD somme et produit de 2 nombres ou vecteurs-ligne
% Usage: R=FSOMPROD(V1,V2)
% Retourne matrice R contenant: en 1ère ligne la
% somme de V1 et V2, en seconde ligne le produit de
% V1 et V2 élément par élément
if nargin~=2
error('cette fonction attend 2 arguments')
end
sa=size(a); sb=size(b);
if ~ isequal(sa,sb)
error('les 2 arguments n'ont pas la même dimension')
end
if sa(1)~=1 || sb(1)~=1
error('les arg. doivent être scalaires ou vecteurs-ligne')
end
resultat(1,:)=a+b; % 1ère ligne de la matrice-résultat
resultat(2,:)=a.*b; % 2ème ligne de la matrice-résultat,
% produit élément par élément !
return % sortie de la fonction (instruction ici pas
% nécessaire vu qu'on a atteint fin fonction)
end % pas nécessaire si le fichier ne contient que cette fct
|
Remarque : cette façon de retourner le résultat (sur une seule variable) ne permet pas de passer à cette fonction des matrices.
r=fsomprod(4,5)
r=fsomprod([2 3 1],[1 2 2]) |
function [somme,produit] = fsomprod(a,b)
%FSOMPROD somme et produit de 2 nombres, vecteurs ou matrices
% Usage: [S,P]=FSOMPROD(V1,V2)
% Retourne matrice S contenant la somme de V1 et V2,
% et matrice P contenant le produit de V1 et V2
% élément par élément
if nargin~=2
error('cette fonction attend 2 arguments')
end
if ~ isequal(size(a),size(b))
error('les 2 arg. n'ont pas la même dimension')
end
somme=a+b;
produit=a.*b; % produit élément par élément !
return % sortie de la fonction (instruction ici pas
% nécessaire vu qu'on a atteint fin fonction)
end % pas nécessaire si le fichier ne contient que cette fct
|
Remarque : cette façon de retourner le résultat (sur deux variable) rend possible le passage de matrices à cette fonction !
[s,p]=fsomprod(4,5)
[s,p]=fsomprod([2 3;1 2],[1 2; 3 3]) |
Un pointeur de fonction (function handle) est une technique alternative d'invocation d'une fonction. L'intérêt réside dans le passage de fonctions à d'autres fonctions et la définition de fonctions anonymes (voir ci-dessous). Les pointeurs de fonctions sont notamment beaucoup utilisés pour définir les callbacks dans les interfaces utilisateurs graphiques (voir chapitre "Programmation GUI").
Ex:si l'on défini f = @sin ;, on peut tracer le graphique de cette fonction avec fplot(f, [0 2*pi]) (qui est équivalent à fplot(@sin, [0 2*pi])) on peut bien entendu ensuite calculer le sinus de π avec f(pi) qui est équivalent à feval(f, pi)
Une fonction anonyme (anonymous function) est une façon très concise de définir une fonction-utilisateur basée sur une expression.
Ex:on pourrait définir la fonction "carré" avec carre = @(nb) nb.^2 ; puis l'invoquer avec carre([2 3 4]) qui retournera [4 9 16]
ou la grapher avec fplot(carre, [0 3]), ou tracer la fonction carré de façon complètement anonyme avec fplot(@(nb) nb.^2, [0 3])la fonction somme = @(nb1, nb2) nb1+nb2 ; implémente la somme de 2 variables, et somme([2 3], [4 1]) retournera donc [6 4]
Ex:on pourrait définir la fonction "carré" avec carre = inline('nb.^2') ; puis l'invoquer avec carre([2 3 4]) qui retournera [4 9 16] la fonction somme = inline('nb1+nb2', 'nb1', 'nb2') implémente la somme de 2 variables, et somme([2 3], [4 1]) retournera donc [6 4]
Lorsque du code MATLAB est exécuté, il est automatiquement interprété et traduit ("parsing") dans un langage de plus bas niveau qui s'appelle le P-Code (pseudo-code). Sous MATLAB seulement, s'agissant d'une fonction souvent utilisée, on peut éviter que cette "passe de traduction" soit effectuée lors de chaque appel en sauvegardant le P-Code sur un fichier avec la commande pcode nom_fonction. Un fichier de nom nom_fonction.p est alors déposé dans le répertoire courant (ou dans le dossier où se trouve le M-file si l'on ajoute à la commande pcode le paramètre -inplace), et à chaque appel la fonction pourra être directement exécutée sur la base du P-Code de ce fichier sans traduction préalable, ce qui peut apporter des gains de performance.
Le mécanisme de conversion d'une fonction ou d'un script en P-Code offre également la possibilité de distribuer ceux-ci à d'autres personnes sous forme binaire en conservant la maîtrise du code source.
Nous énumérons encore ici quelques commandes ou fonctions supplémentaires qui peuvent être utiles dans la programmation de scripts ou de fonctions.
return
Ex: voir ci-après
Ex: soit la fonction test_vararg.m suivante :
function test_vararg(varargin)
fprintf('Nombre d''arguments passes a la fonction : %d \n',nargin)
for no_argin=1:nargin
fprintf('- argument %d:\n', no_argin)
disp(varargin{no_argin} )
end
end
Nombre d'arguments passes a la fonction : 4
- argument 1:
111
- argument 2:
22 33
44 55
- argument 3:
hello !
- argument 4:
{ [1,1] = ca va ? }
Ex: A l'intérieur d'une fonction-utilisateur mafonction :
• lorsqu'on l'appelle avec mafonction(...) : nargout vaudra 0
• lorsqu'on l'appelle avec out1 = mafonction(...) : nargout vaudra 1
• lorsqu'on l'appelle avec [out1 out2] = mafonction(...) : nargout vaudra 2, etc...
Ex d'instruction dans une fonction : warning(['La fonction ' mfilename ' attend au moins un argument'])
Ex : la fonction fct1.m ci-dessous mémorise (et affiche) le nombre de fois qu'elle a été appelée :
function fct1
global COMPTEUR
COMPTEUR=COMPTEUR+1;
fprintf('fonction appelee %04u fois \n',COMPTEUR)
endglobal COMPTEUR % cela déclare le compteur également global dans le workspace COMPTEUR = 0 ; % initialisation du compteur fct1 % => cela affiche "fonction appelee 1 fois" fct1 % => cela affiche "fonction appelee 2 fois"
Ex : la fonction fct2.m ci-dessous mémorise (et affiche) le nombre de fois qu'elle a été appelée. Contrairement à l'exemple de la fonction fct1.m ci-dessus, la variable compteur n'a pas à être déclarée dans la session principale (ou dans le script depuis lequel on appelle cette fonction), et le compteur doit ici être initialisé dans la fonction.
function fct2
persistent compteur
% au premier appel, après cette déclaration persistent compteur existe et vaut []
if isempty(compteur)
compteur=0 ;
end
compteur=compteur+1 ;
fprintf('fonction appelee %04u fois \n',compteur)
endfct2 % => cela affiche "fonction appelee 1 fois" fct2 % => cela affiche "fonction appelee 2 fois"
Ex: le petit script suivant permet de grapher n'importe quelle fonction y=f(x) définie interactivement par l'utilisateur :
fonction = input('Quelle fonction y=fct(x) voulez-vous grapher : ','s');
min_max = input('Indiquez [xmin xmax] : ');
x = linspace(min_max(1),min_max(2),100);
eval(fonction,'error(''fonction incorrecte'')');
plot(x,y)
endLorsqu'il s'agit de charger, dans MATLAB/Octave, une matrice à partir de données externes stockées dans un fichier-texte, les commandes load -ascii et dlmread/dlmwrite, présentées au chapitre "Workspace MATLAB/Octave", sont suffisantes. Mais lorsque les données à importer sont dans un format plus complexe ou qu'il s'agit d'importer du texte ou d'exporter des données vers d'autres logiciels, les fonctions présentées ci-dessous s'avèrent nécessaires.
Le tableau ci-dessous donne une vision synthétique des principales fonctions d'entrée/sortie (présentées en détail dans les chapitres qui suivent). Notez que :
| Écriture | Lecture | |
| Interactivement |
Écriture à l'écran (sortie standard) • non formaté: disp(variable|chaîne) (avec un seul paramètre !) • formaté: fprintf(format, variable(s)) (ou printf...)
|
Lecture au clavier (entrée standard) • non formaté: var = input(prompt {, 's'} ) • formaté: var = scanf(format)
|
| Sur chaîne de caractères |
• string = sprintf(format, variable(s)) • autres fonctions : mat2str ... |
• var|mat = sscanf(string, format {,size}) • [var1, var2... ] = strread(string,format {,n}) • autres fonctions : textscan ... |
| Sur fichier texte |
• fprintf(file_id, format, variable(s)... ) • autres fonctions : save -ascii, dlmwrite ... |
• var = fscanf(file_id, format {,size}) • line = fgetl(file_id) • string = fgets(file_id {,nb_car}) • autres fonctions : load(fichier), textread, textscan, fileread, dlmread ... |
|
Via internet (protocoles HTTTP, FTP ou FILE) |
• string = urlread(url, method, param) • urlwrite(url, fichier, method, param) (pour url de type HTTP, method : 'get' ou 'post') • autres fonctions : webread et webwrite (RESTful web services ) |
• string = urlread(url) • urlwrite(url, fichier) • autres fonctions : webread et webwrite (RESTful web services ) |
| Sur fichier binaire | • autres fonctions : fwrite, xlswrite ... | • autres fonctions : fread, xlsread ... |
|
08:10 min |
Les spécifications de format et leur usage dans l'écriture et décodage de chaînes |
Les différentes fonctions de lecture/écriture sous forme texte présentées ci-dessous font appel à des "formats" (parfois appelés "templates" dans la documentation). Le but de ceux-ci est de :
Les formats sont des chaînes de caractères se composant de "spécifications de conversion" dont la syntaxe est décrite dans le tableau ci-dessous.
 ATTENTION : dans un format de lecture (sscanf, fscanf), on ne préfixera en principe pas les "spécifications de conversion" de nombres (u d i o x X f e E g G) par des valeurs n (taille du champ) et m (nombre de décimales), car le comportement de MATLAB et de Octave peut alors conduire à des résultats différents (découpage avec MATLAB, et aucun effet sous Octave).
ATTENTION : dans un format de lecture (sscanf, fscanf), on ne préfixera en principe pas les "spécifications de conversion" de nombres (u d i o x X f e E g G) par des valeurs n (taille du champ) et m (nombre de décimales), car le comportement de MATLAB et de Octave peut alors conduire à des résultats différents (découpage avec MATLAB, et aucun effet sous Octave).
Ex: sscanf('560001','%4f') retourne : sous MATLAB le vecteur [5600 ; 1] , et sous Octave la valeur 560001
| Spécifications | Description |
| espace |
• En lecture (sscanf, fscanf) : les caractères espace dans un format sont ignorés (i.e. n'ont aucune signification) ! • En écriture (sprintf, fprintf) : les caractères espace dans un format sont écrits dans la chaîne résultante ! |
|
%u
%nu |
Correspond à un nombre entier positif (non signé)
• En lecture: |
|
%d %i
|
Correspond à un nombre entier positif ou négatif
• En lecture: |
|
%o
%no |
Correspond à un nombre entier positif en base octale
• En lecture: |
|
%x %X
%nx %nX |
Correspond à un nombre entier positif en base hexadécimale
• En lecture: |
|
%f
|
Correspond à un nombre réel sans exposant (de la forme {-}mmm.nnn)
• En lecture: |
|
%e %E
%n.me %n.mE |
Correspond à un nombre réel en notation scientifique (de la forme {-}m.nnnnnE{+|-}xxx)
• En lecture: |
|
%g %G
%ng %nG |
Correspond à un nombre réel en notation scientifique compacte (de la forme {-}m.nnnnnE{+|-}x)
• En lecture: |
|
%c
%nc |
Correspond à 1 ou n caractère(s), y compris d'éventuels caractères espace
• En lecture: |
|
%s
%ns |
Correspond à une chaîne de caractères
• En lecture: les chaînes sont délimitées par un ou plusieurs caractères espace |
|
Caractères spéciaux |
Pour faire usage de certains caractères spéciaux, il est nécessaire de les encoder de la façon suivante : • \n pour un saut à la ligne suivante (new line) • \t pour un tab horizontal • %% pour le caractère "%" • \\ pour le caractère "\" |
|
Tout autre caractère |
Tout autre caractère (ne faisant pas partie d'une spécification %...) sera utilisé de la façon suivante :
• En lecture: le caractère "matché" sera sauté. Exception: les caractères espace dans un format de lecture sont ignorés |
De plus, les "spécifications de conversion" peuvent être modifiées (préfixées) de la façon suivante :
| Spécifications | Description |
| %-n... |
• En écriture: l'élément sera justifié à gauche (et non à droite) dans un champ de n car. au min.
Ex: sprintf('|%-5s|%-5.1f|', 'abc', 12) => '|abc |12.0 |' |
| %0n... |
• En écriture: l'élément sera complété à gauche par des '0' (chiffres zéros, et non caractères espace) dans un champ de n car. au min.
Ex: sprintf('|%05s|%05.1f|', 'abc', 12) => '|00abc|012.0|' |
| %*... |
• En lecture: saute l'élément qui correspond à la spécification qui suit
Ex: sscanf('12 blabla 34.5 67.8', '%d %*s %*f %f') => [12 ; 67.8] |
La fonction sscanf ("string scan formated") permet, à l'aide d'un format de lecture, de décoder le contenu d'une chaîne de caractère et d'en récupérer les données sur un vecteur ou une matrice. La lecture s'effectue en "format libre" en ce sens que sont considérés, comme séparateurs d'éléments dans la chaîne, un ou plusieurs espace ou tab. Si la chaîne renferme davantage d'éléments qu'il n'y a de "spécifications de conversion" dans le format, le format sera "réutilisé" autant de fois que nécessaire pour lire toute la chaîne. Si, dans le format, on mélange des spécifications de conversion numériques et de caractères, il en résulte une variable de sortie (vecteur ou matrice) entièrement numérique dans laquelle les caractères des chaînes d'entrée sont stockés, à raison d'un caractère par élément de vecteur/matrice, sous forme de leur code ASCII.
vec = sscanf(string, format)
Ex:
• vec=sscanf('abc 1 2 3 4 5 6', '%*s %f %f') => vec=[1;2;4;5]
Notez que, en raison de la "réutilisation" du format, les nombres 3 et 6 sont ici sautés par le %*s !
• vec=sscanf('1001 1002 abc', '%f %f %s') => vec=[1001;1002;87;98;99]
Mélange de spécifications de conversion numériques et de caractères => la variable 'vec' est de type nombre, et la chaîne 'abc' y est stockée par le code ASCII de chacun de ses caractères
Ex:
• vec=sscanf('1 2 3 4 5 6', '%f', 4) => vec=[1;2;3;4]
• [mat,ct]=sscanf('1 2 3 4 5 6', '%f', [3,2]) => mat=[1 4 ; 2 5 ; 3 6], ct=6
• [mat,ct]=sscanf('1 2 3 4 5 6', '%f', [2,3]) => mat=[1 3 5 ; 2 4 6], ct=6
[var1, var2, var3 ...] = sscanf(string, format, 'C')
Ex:
• [str,nb1,nb2]=sscanf('abcde 12.34 45.3e14 fgh', '%3c %*s %f %f', 'C') => str='abc', nb1=12.34, nb2=4.53e+15
[var1, var2, var3... ] = strread(string, format {,n} {,'delimiter',delimiteur})
Ex:
• [str,nb1,nb2]=strread('abcde 1.23 4.56 fgh 7.98 10.1', '%s%f%f', 1) => str={'abcde'}, nb1=1.23, nb2=4.56 ; format utilisé 1x
• [str,nb1,nb2]=strread('abcde 1.23 4.56 fgh 7.98 10.1', '%s%f%f') => str={'abcde' ; 'fgh'}, nb1=[1.23 ; 7.98], nb2=[4.56 ; 10.1] ; format ici utilisé 2x
• [nb1,int2,nb3]=strread('1.23 ** 4.56 ## 7.89', '%f ** %u %* %f') => nb1=1.23, int2=5, nb3=7.89 ; '**' étant explicitement sauté, de même que '##' qui est matché par %*
• [nb1,nb2]=strread('1.2 # 3.4 * 5.6 # 7.8', '%f%f','delimiter','*#') => nb1=[1.2 ; 5.6], nb2=[3.4 ; 7.8] ; usage des délimiteurs espace, * et #
Rappelons que si une chaîne ne contient que des nombres, on peut aussi aisément récupérer ceux-ci à l'aide de la fonction str2num présentée au chapitre sur les "Chaînes de caractères".
La fonction sprintf ("string print formated") lit les variables qu'on lui passe et les retourne, de façon formatée, sur une chaîne de caractère. S'il y a davantage d'éléments parmi les variables que de "spécifications de conversion" dans le format, le format sera "réutilisé" autant de fois que nécessaire.
string = sprintf(format, variable(s)... )
Ex:
• nb=4 ; prix=10 ; disp(sprintf('Nombre d''articles: %04u Montant: %0.2f Frs', nb, nb*prix))
ou, plus simplement: fprintf('Nombre d''articles: %04u Montant: %0.2f Frs \n', nb, nb*prix)
=> affiche: Nombre d'articles: 0004 Montant: 40.00 Frs
La fonction mat2str ("matrix to string") décrite ci-dessous (et voir chapitre "chaînes de caractères") est intéressante pour sauvegarder de façon compacte sur fichier des matrices sous forme texte (en combinaison avec fprintf) que l'on pourra relire sous MATLAB/Octave (lecture-fichier avec fscanf, puis affectation a une variable avec eval).
Ex:
• str_mat = mat2str(eye(3,3)) produit la chaîne "[1 0 0;0 1 0;0 0 1]"
• et pour affecter ensuite les valeurs d'une telle chaîne à une matrice x, on ferait eval(['x=' str_mat])
Voir aussi les fonctions plus primitives int2str (conversion nombre entier->chaîne) et num2str (conversion nombre réel->chaîne).
|
14:56 min |
Quel que soit le langage utilisé (MATLAB/Octave, Python, C, Java...), la grande majorité des programmes que l'on développe sont appelés à manipuler des données qui doivent être persistantes, c'est-à-dire stockées sous forme de fichiers sur disque. Bien souvent aussi ces programmes ne travaillent pas seuls, c'est-à-dire qu'ils utilisent des données produites par d'autres logiciels, ou fournissent des données à d'autres programmes.
Il existe fondamentalement 2 types de fichiers : les fichiers binaires et les fichiers texte : • les fichiers binaires ne sont pas lisibles par un oeil humain, et leur contenu n'est souvent pas documenté, donc seul le programme qui les a créé peut les utiliser (exemple: les fichiers au format natifs manipulés par un tableur tel que LibreOffice Calc ou Microsoft Excel...) • les fichiers-texte, quant à eux, sont directement lisibles par l'être humain et modifiables dans un éditeur ; et c'est ce type de fichier qui est le plus utilisé lorsqu'on échange des données entre différents programmes (exemple: le format CSV...) Nous présentons dans cette vidéo la lecture et l'écriture de fichiers texte sous MATLAB/Octave, et utilisons pour cela les "formats", concept présenté dans la vidéo précédente. |
Ex: Dans l'exemple ci-dessous, la première instruction "avale" le fichier essai.txt sur le vecteur ligne de type chaîne fichier_entier (vecteur ligne, car on transpose le résultat de fileread). La seconde découpe ensuite cette chaîne selon les sauts de ligne (\n) de façon à charger le tableau cellulaire tabcel_lignes à raison d'une ligne du fichier par cellule.
fichier_entier = fileread('essai.txt')' ;
tabcel_lignes = strread(fichier_entier, '%s', 'delimiter', '\n') ;
Les "spécifications de conversion" de format %f, %s, %u et %d peuvent être utilisées avec textread sous MATLAB et Octave.
Sous Octave seulement on peut en outre utiliser les spécifications %o et %x.
Sous MATLAB, les spécifications %u et %d génèrent un vecteur réel double précision. Mais ATTENTION, sous Octave elles génèrent un vecteur entier 32 bits !
Sous MATLAB seulement on peut encore utiliser :
%[...] : lit la plus longue chaîne contenant les caractères énumérés entre [ ]
%[^...] : lit la plus longue chaîne non vide contenant les caractèrens non énumérés entre [ ]
Ex:
Soit le fichier-texte de données ventes.txt suivant :
et le script MATLAB/Octave suivant :10001 Dupond Livres 12 23.50 10002 Durand Classeurs 15 3.95 10003 Muller DVDs 5 32.00 10004 Smith Stylos 65 2.55 10005 Rochat CDs 25 15.50 10006 Leblanc Crayons 100 0.60 10007 Lenoir Gommes 70 2.00
[No_client, Nom, Article, Nb_articles, Prix_unit] = textread('ventes.txt', '%f %s %s %f %f') ;
Montant = Nb_articles .* Prix_unit ;
disp(' Client [No ] Nb Articles Prix unit. Montant ')
disp(' --------- ------- ----- --------- ----------- ------------')
format = ' %10s [%d] %5d %-10s %8.2f Frs %8.2f Frs\n' ;
for no=1:1:length(No_client)
fprintf(format, Nom{no}, No_client(no), Nb_articles(no), Article{no}, Prix_unit(no), Montant(no) ) ;
end
fprintf('\n\n TOTAL %8.2f Frs \n', sum(Montant) ) L'exécution de ce script: lit le fichier, calcule les montants, et affiche ce qui suit :
Client [No ] Nb Articles Prix unit. Montant
--------- ------- ----- --------- ----------- ------------
Dupond [10001] 12 Livres 23.50 Frs 282.00 Frs
Durand [10002] 15 Classeurs 3.95 Frs 59.25 Frs
Muller [10003] 5 DVDs 32.00 Frs 160.00 Frs
Smith [10004] 65 Stylos 2.55 Frs 165.75 Frs
Rochat [10005] 25 CDs 15.50 Frs 387.50 Frs
Leblanc [10006] 100 Crayons 0.60 Frs 60.00 Frs
Lenoir [10007] 70 Gommes 2.00 Frs 140.00 Frs
TOTAL 1254.50 FrsSi file_name ne définit qu'un nom de fichier, celui-ci est recherché dans le répertoire courant. Si l'on veut ouvrir un fichier se trouvant dans un autre répertoire, il faut bien entendu faire précéder le nom du fichier de son chemin d'accès (path) relatif ou absolu. S'agissant du séparateur de répertoire, bien que celui-ci soit communément \ sous Windows, nous vous conseillons de toujours utiliser / (accepté par MATBAL/Octave sous Windows) pour que vos scripts/fonctions soient portables, c'est-à-dire utilisables dans les 3 mondes Windows, macOS et GNU/Linux.
Le mode d'accès au fichier sera défini par l'une des chaînes suivantes :
• 'rt' ou 'rb' ou 'r' : lecture seule (read)
• 'wt' ou 'wb' ou 'w' : écriture (write), avec création du fichier si nécessaire, ou écrasement s'il existe
• 'at' ou 'ab' ou 'a' : ajout à la fin du fichier (append), avec création du fichier si nécessaire
• 'rt+' ou 'rb+' ou 'r+' : lecture et écriture, sans création
• 'wt+' ou 'wb+' ou 'w+' : lecture et écriture avec écrasement du contenu
• 'at+' ou 'ab+' ou 'a+' : lecture et ajout à la fin du fichier, avec création du fichier si nécessaire
Le fait de spécifier t ou b ou aucun de ces deux caractères dans le mode a la signification suivante :
• t : ouverture en mode "texte"
• b ou rien : ouverture en mode "binaire" (mode par défaut)
Sous Windows ou macOS, il est important d'utiliser le mode d'ouverture "texte" si l'on veut que les fins de ligne soient correctement interprétées !
En cas d'échec (fichier inexistant en lecture, protégé en écriture, etc...), file_id reçoit la valeur "-1". On peut aussi récupérer un message d'erreur sous forme de texte explicite sur message_err
Identifiants prédéfinis (toujours disponibles, correspondant à des canaux n'ayant pas besoin d'être "ouverts") :
• 1 ou stdout : correspond à la sortie standard (standard output, c'est-à-dire fenêtre console MATLAB/Octave), pouvant donc être utilisé pour l'affichage à l'écran
• 2 ou stderr : correspond au canal erreur standard (standard error, par défaut aussi la fenêtre console), pouvant aussi être utilisé par le programmeur pour l'affichage d'erreurs
• 0 ou stdin : correspond à l'entrée standard (standard input, c'est-à-dire saisie au clavier depuis console MATLAB/Octave).
Pour offrir à l'utilisateur la possibilité de désigner le nom et emplacement du fichier à ouvrir/créer à l'aide d'une fenêtre de dialogue classique (interface utilisateur graphique), on se référera aux fonctions uigetfile (lecture de fichier) et uiputfile (écriture de fichier) présentées au chapitre "Fenêtres de sélection de fichiers". Pour sélectionner un répertoire, on utilisera la fonction uigetdir.
freport()
{status=} fclose(file_id) variable = fscanf(file_id, format {,size})
Ex:
Soit le fichier-texte suivant :
La lecture des données de ce fichier avec fscanf s'effectuerait de la façon suivante :10001 Dupond Livres 12 23.50 10002 Durand Classeurs 15 3.95
file_id = fopen('fichier.txt', 'rt') ;
no = 1 ;
while ~ feof(file_id)
No_client(no) = fscanf(file_id,'%u',1) ;
Nom{no,1} = fscanf(file_id,'%s',1) ;
Article{no,1} = fscanf(file_id,'%s',1) ;
Nb_articles(no) = fscanf(file_id,'%u',1) ;
Prix_unit(no) = fscanf(file_id,'%f',1) ;
no = no + 1 ;
end
status = fclose(file_id) ;Ex: voir l'usage de cette fonction dans l'exemple fscanf ci-dessus
{count=} fprintf(file_id, format, variable(s)... )
{count=} fprintf(format, variable(s)... ) {count=} printf(format, variable(s)... )
printf (spécifique à Octave), provoque une écriture/affichage à l'écran (i.e. dans la fenêtre de commande MATLAB/Octave).
Ex: affichage de la fonction y=exp(x) sous forme de tableau avec :
x=0:0.05:1 ; exponentiel=[x;exp(x)] ; fprintf(' %4.2f %12.8f \n',exponentiel)
{status=} fflush(file_id)
fflush(stdout). Voyez aussi la fonction page_output_immediately pour carrément désactiver le buffering.
Ex: on peut lire le fichier ventes.txt ci-dessus avec :
file_id = fopen('ventes.txt', 'rt');
vec_cel = textscan(file_id, '%u %s %s %u %f');
fclose(file_id);Les paramètres optionnels sont :
doc, pdf (ce dernier nécessitant pdflatex c-à-d. texlive sous Linux) ;
Ex: Soit le script ci-dessous nommé code.m :
% Exécution/publish de ce code sous Octave
% Données
x= 4*rand(1,50) -2 % val. aléatoires entre -2 et +2
y= 4*rand(1,50) -2 % val. aléatoires entre -2 et +2
z= x.*exp(-x.^2 - y.^2) % Z en ces points
% Premier graphique (double, de type multiple plots)
figure(1)
subplot(1,2,1)
plot(x,y,'o')
title('semis de points aleatoire')
grid('on')
axis([-2 2 -2 2])
axis('equal')
subplot(1,2,2)
tri_indices= delaunay(x, y); % form. triangles => matr. indices
trisurf(tri_indices, x, y, z) % affichage triangles
title('z = x * exp(-x^2 - y^2) % sur ces points')
zlim([-0.5 0.5])
set(gca,'ztick',-0.5:0.1:0.5)
view(-30,10)
% Second graphique (simple)
figure(2)
xi = -2:0.2:2 ;
yi = xi';
[XI,YI,ZI] = griddata(x,y,z,xi,yi,'nearest'); % interp. grille
surfc(XI,YI,ZI)
title('interpolation sur grille')
|
Son exécution avec la commande : publish('code.m', 'format','html', 'imageFormat','png') produit le rapport accessible sous ce lien |
Lorsqu'il s'agit de débuguer un script ou une fonction qui pose problème, la première idée qui vient à l'esprit est de parsemer le code d'instructions d'affichages intermédiaires. Plutôt que de faire des disp, on peut alors avantageusement utiliser la fonction warning présentée plus haut, celle-ci permettant en une seule instruction d'afficher du texte et des variables ainsi que de désactiver/réactiver aisément l'affichage de ces warnings. Mais il existe des fonctionnalités de debugging spécifiques présentées ci-après.
keyboard('prompt ')
K>>, respectivement debug> ou le prompt spécifié). L'utilisateur peut alors travailler normalement en mode interactif dans MATLAB/Octave (visualiser ou changer des variables, passer des commandes...). Puis il a le choix de : Les éditeurs/débuggers intégrés de MATLAB et de Octave GUI (depuis Octave 3.8) permettent de placer visuellement des breakpoints (points d'arrêt) dans vos scripts/fonctions, puis d'exécuter ceux-ci en mode step-by-step (instructions pas à pas). L'intérêt réside dans le fait que lorsque l'exécution est suspendue sur un breakpoint ou après un step, vous pouvez, depuis la fenêtre de console à la suite du prompt K>> ou debug>, passer interactivement toute instruction MATLAB/Octave (p.ex. vérifier la valeur d'une variable, la modifier...), puis poursuivre l'exécution. Par rapport à la méthode keyboard ci-dessus, l'avantage ici est qu'on ne "pollue" pas notre code d'instructions provisoires.
Les boutons décrits ci-dessous se cachent dans l'onglet EDITOR du bandeau MATLAB, et dans palette d'outils de l'éditeur intégré de Octave GUI.
A) Mise en place de breakpoints :
F12, Breakpoint > Set/Clear, Toggle Breakpoint : place/supprime un breakpoint sur la ligne courante, symbolisé par un disque rouge ● (identique à dbstop/dbclear)
Next Breakpoint et Previous Breakpoint : déplace le curseur d'édition au beakpoint suivant/précédent du fichier
Breakpoints > Clear all, Remove All Breakpoints : supprime tous les breakpoints qui ont été définis
B) Puis exécution step-by-step :
K>> ou debug>
Quit Debugging, Exit Debug Mode ou maj-F5 : interrompt définitivement l'exécution (identique à dbquit)
A) Mise en place de breakpoints :
dbstop in script|fonction at no dbstop('script|fonction', no {, no, no...} ) ou dbstop('script|fonction', vecteur_de_nos)
dbclear in script|fonction at no respectivement
dbclear in script|fonction dbclear('script|fonction', no {, no, no...} ) respectivement
dbclear('script|fonction')
dbstatus {script|fonction} dbstatus {('script|fonction')}
K>> ou debug>
enter : la commande de debugging précédemment passée est répétée ; sous MATLAB, faire curseur-hautenter
dbwhere : affichage du numéro (et contenu) de la ligne courante du script/fonction
Pour déterminer le temps CPU utilisé dans certaines parties de vos scripts ou fonctions, une alternative aux outils de profiling ci-dessous serait d'ajouter manuellement dans votre code des fonctions de "timing" (chronométrage du temps consommé) décrites au chapitre "Dates et temps", sous-chapitre "Fonctions de timing et de pause".
Enclencher/déclencher le processus de profiling :
profile viewer ou profile('viewer') ou profview
profexport(path, {nom,} prof_struct) (depuis Octave 4.2)
profshow(prof_struct {, N })
profexplore(prof_struct)
Script demo_profiling.m :
%DEMO_PROFILING Script illustrant, par
% profiling, l'utilité de vectoriser son code !
t0=cputime; % compteur temps CPU consommé
% Génération matrice aléatoire
nb_l = 1000;
nb_c = 500;
v_min = -10 ;
v_max = 30 ;
mat = matrice_alea(nb_l, nb_c, v_min, v_max) ;
% Extraction de certains éléments de mat
vmin = 0 ;
vmax = 20 ;
vec = extrait_matrice(mat, vmin, vmax) ;
% Calcul de la moyenne des éléments extraits
if CODE_VECTORISE % Code vectorisé :-)
moyenne_vect = mean(vec) ;
else % Code non vectorisé :-(
somme_elem = 0 ;
for indice=1:length(vec)
somme_elem = somme_elem + vec(indice) ;
end
moyenne_vect = somme_elem / length(vec) ;
end
% Affichages...
moyenne_vect
duree_calcul=cputime-t0
|
Fonction matrice_alea.m :
function [matrice]=matrice_alea(nb_l,nb_c,v_min,v_max)
% MATRICE_ALEA(NB_L, NB_C, V_MIN, V_MAX)
% Generation matrice de dimension (NB_L, NB_C)
% de nb aleatoires compris entre V_MIN et V_MAX
global CODE_VECTORISE
v_range = v_max - v_min ;
if CODE_VECTORISE % Code vectorisé :-)
matrice = (rand(nb_l, nb_c) * v_range) + v_min ;
else % Code non vectorisé :-(
for lig=1:nb_l
for col=1:nb_c
matrice(lig,col) = (rand()*v_range) + v_min ;
end
end
end
return
Fonction extrait_matrice.m :
function [vecteur] = extrait_matrice(mat, vmin, vmax)
% EXTRAIT_MATRICE(MAT, VMIN, VMAX)
% Extrait de la matrice MAT, parcourue col. apres
% colonne, tous les elements dont la val. est
% comprise entre VMIN et VMAX, et les retourne
% sur un vecteur colonne
global CODE_VECTORISE
if CODE_VECTORISE % Code vectorisé (index. logique) :-)
vecteur=mat(mat>=vmin & mat<=vmax);
else % Code non vectorisé :-(
indice = 1;
for col=1:size(mat,2)
for lig=1:size(mat,1)
if (mat(lig,col) >= vmin) && (mat(lig,col) <= vmax)
vecteur(indice) = mat(lig,col) ;
indice = indice + 1 ;
end
end
end
vecteur = vecteur' ;
end
return
|
Vous constatez que, pour les besoins de l'exemple, ces codes comportent du code vectorisé (usage de fonctions vectorisées, indexation logique...) et du code non vectorisé (usage de boucles for/end). Nous avons délimité ces deux catégories de codes par des structures if/else/end s'appuyant sur une variable globale nommée CODE_VECTORISE.
Réalisons maintenant le profiling de ce code. En premier lieu, il faut rendre globale au niveau workspace et du script la variable CODE_VECTORISE (ceci est déjà fait dans les fonctions), avec l'instruction :
Commençons par l'examen du code non vectorisé :
Puis sous MATLAB :
Ou sous Octave : Poursuivons maintenant avec l'examen du code vectorisé (remplacement des boucles par des fonctions vectorisées et l'indexation logique) :
Puis sous MATLAB :
Ou sous Octave : Évitez autant que possible les boucles for, while... en utilisant massivement les capacités vectorisées de MATLAB/Octave (la plupart des fonctions admettant comme arguments des tableaux). Pensez aussi à l'"indexation logique".
Redimensionner dynamiquement un tableau dans une boucle peut être très coûteux en temps CPU. Il est plus efficace de pré-allouer l'espace du tableau avant d'entrer dans la boucle, quitte à libérer ensuite l'espace non utilisé. Considérons par exemple la boucle ci-dessous :
Les nombres sont par défaut stockés en virgule flottante "double précision" (16 chiffres significatifs) occupant en mémoire 8 octets par nombre (64 bits). Si vous gérez des gros tableaux de nombres qui ne nécessitent pas cette précision, un gain de place important peut être obtenu en initialisant ces tableaux en virgule flottante "simple précision" (7 chiffres significatifs) occupant 4 octets par élément. S'il s'agit de nombre entiers, envisagez les types entiers 32 bits (plage de -2'147'483'648 à 2'147'483'647), 16 bits (de -32'768 à 32'767) ou 8 bits (-128 à 127). Voyez pour cela notre chapitre "Types de nombres".
Si vous manipulez des matrices comportant beaucoup d'éléments nuls (vous pouvez visualiser cela avec spy(matrice)), pensez à les stocker sous forme sparse (conversion avec sparse(matrice), et conversion inverse avec full(sparse)). Elles occuperont moins d'espace mémoire, et les opérations de calcul s'en trouveront accélérées (réduction du nombre d'opérations, celles portant sur les zéros n'étant pas effectuées).
